

这次Pi币真的上线主网了!
有结构化推理和先验知识,智能体变得更加通用了。
原文来源:机器之心

图片来源:由无界 AI生成
自 AI 诞生以来,开发能够解决和适应复杂工作的多任务智能体(Agent)一直是个重要的目标。
AI 智能体对于许多应用至关重要,研究者通常用强化学习方法通过环境交互来培养智能体的决策技能。基于模型和无模型的深度强化学习方法都已取得了广为人们所知的成就,例如 AlphaZero、改进的排序和乘法算法、无人机竞速以及聚变反应堆中的等离子体控制。这些成功涉及一个标准的强化学习管道,智能体在其中学习我们所说的外在功能 —— 一种直接与外界交互的策略,即响应环境刺激以最大化奖励信号。该函数通常是参数化神经网络,根据环境观察生成动作。
经典的强化学习方法使用单个映射函数来定义策略 π,但在复杂的环境中通常被证明是不够的,这与通用智能体在多个随机环境中交互、适应和学习的目标相矛盾。
在强化学习中引入的先验通常是特定于任务的,并且需要广泛的工程和领域专业知识。为了泛化,最近的研究已转向将大型语言模型(LLM)集成到智能体框架中,如 AutoGen、AutoGPT 和 AgentVerse 等工作。
近日,来自华为诺亚方舟实验室、伦敦大学学院(UCL)、牛津大学等机构的研究者提出了盘古智能体框架(Pangu-Agent)尝试来解决 AI 智能体面临的挑战。该研究作者包括伦敦大学学院计算机系教授汪军。

论文链接:https://arxiv.org/abs/2312.14878
该工作在两个关键方面区别于先前的框架:i)将智能体的内部思维过程形式化为结构化推理的形式;ii)展示了通过监督学习和强化学习来微调智能体的方法。
标准强化学习侧重于直接学习从感知中输出行动的策略。虽然人们习惯于通过深度网络架构参数化策略,但作者认为,当通过基础模型策略跨任务扩展智能体时,标准 RL 管道中缺乏固有推理结构可能会成为一个重大瓶颈,因为梯度无法为所有深度网络提供足够的监督。
盘古 Agent 框架展示了结构化推理如何帮助强化学习克服这些挑战,利用大规模基础模型提供先验知识并实现跨广泛领域的泛化能力。
据介绍,该工作的主要贡献包括:
证明了结构化推理在智能体框架中的重要性,盘古 Agent 的通用性足以有效涵盖现有智能体框架的任务范围。作为一个元智能体框架,它可以利用内部函数调用的顺序进行调整或微调,或者将决策委托给底层 LLM。使用者也可以轻松扩展智能体的功能,并组合或重用许多已经实现的方法。这些发现凸显了结构化推理在基于大模型的智能体训练方面存在不小潜力。
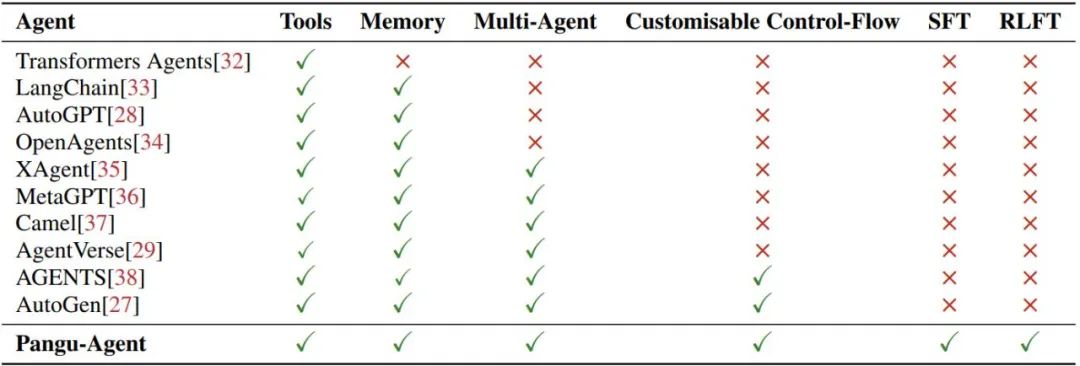
表 1:盘古 Agent 与最近一些大模型智能体的比较。

图 2:三个内在函数的可视化,展示了该工作提出的范式在提高代理的模块化和灵活性方面的重要性。用户可以重新定义和重新配置内在函数,例如 µ1 (・) 以 LLM 作为输入来产生想法,或 µ2 (・) 利用工具来帮助改进推理。新智能体还支持嵌套这些内在函数来构建更通用的模块,以完成复杂且具有挑战性的决策任务。
Pangu-Agent 的范式
为了引入结构化推理,我们假设一系列内在函数 µ(・) 作用于并转换智能体的内部记忆。引入这些内在函数可以将典型的强化学习目标重新表述为支持多个「思考」步骤的目标。因此,典型的 RL 目标旨在找到一个以观察 o→ 的历史为条件的策略 π,以最大化回报 R,即 maxπ(・) R (π(・|o→)) 可以使用嵌套集重写(参见图 . 2) 内函数 µ→ (・) 为:
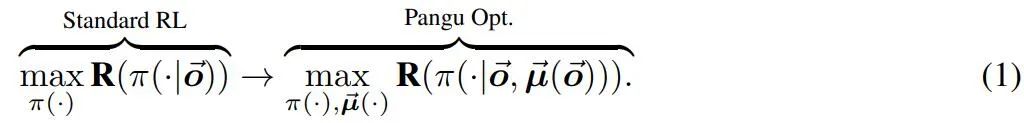
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

