

这次Pi币真的上线主网了!
原文来源:量子位

图片来源:由无界 AI生成
单RTX4090,每秒生成100张图!

一种专为实时交互式图像生成而设计的一站式解决方案,登顶GitHub热榜。
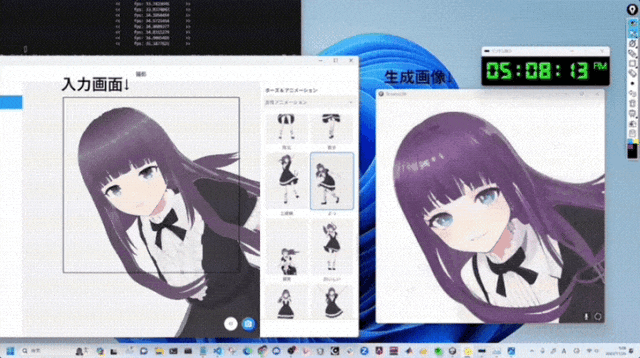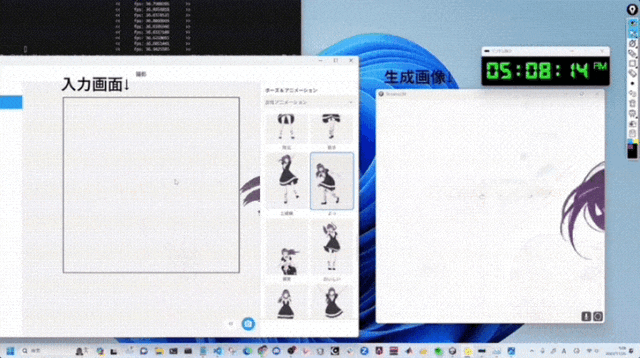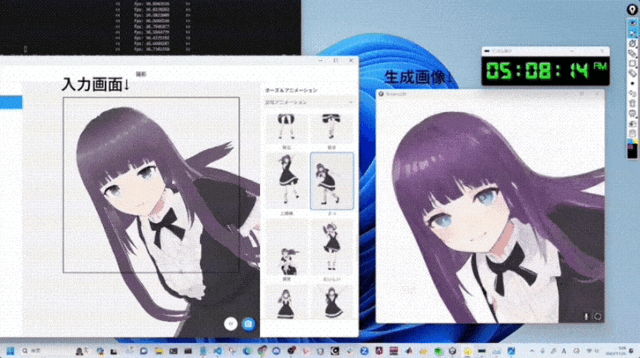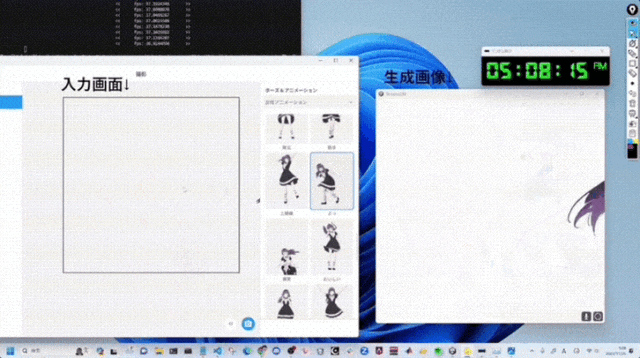
方案名为StreamDiffusion,支持多种模型和输出帧率。

无论是图像到图像,还是文本到图像,都能实时生成:

重点是,该项目现已开源,在GitHub热榜已狂揽3400+星。
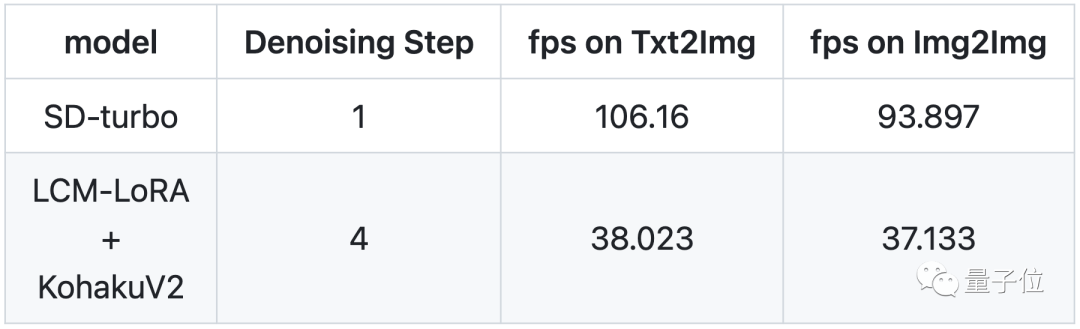
经测试,使用SD-turbo模型在去噪步骤为1步的情况下,文本-图像每秒帧率可达106,图像-图像每秒帧率达到93。
CM-LoRA+KohakuV2模型在4步的情况下,文本-图像每秒帧率为38,图像-图像每秒帧率为37。
除了高吞吐量、低延迟,StreamDiffusion还做到了低功耗。单块RTX3060上,可降低58.2%的功耗;单块RTX4090,降低49.8%。
网友们也是玩嗨了,纷纷上手尝试:
浅浅留下一个字:

StreamDiffusion长啥样?
StreamDiffusion由来自UC伯克利、日本筑波大学等的研究人员联合提出。

StreamDiffusion Pipeline包含六大组件:Stream Batch、残差无分类器指导(RCFG)、输入-输出队列、随机相似性过滤器、KV-Caches预计算、带有小型自动编码器的模型加速工具。
首先Stream Batch,是将原来顺序的去噪步骤改为批量化处理。允许在一个批处理中,每幅图像处于去噪流程的不同阶段。
如此一来,可以大大减少UNet推理次数,显著提高吞吐量。
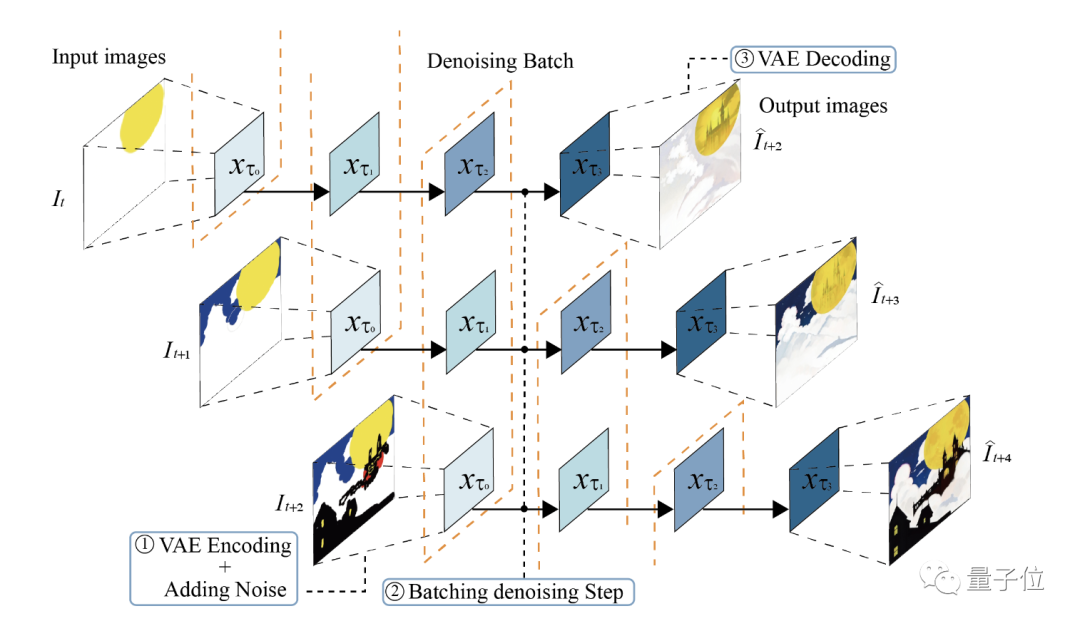
此外,原先的CFG算法中,需要额外大量计算负样本,导致计算效率低下。
RCFG方法则构建一个“虚拟残差噪声”,这样就只需要一次或者零次负样本计算,减少了计算负样本的开销。
相比之前的CFG方法加速了2倍。

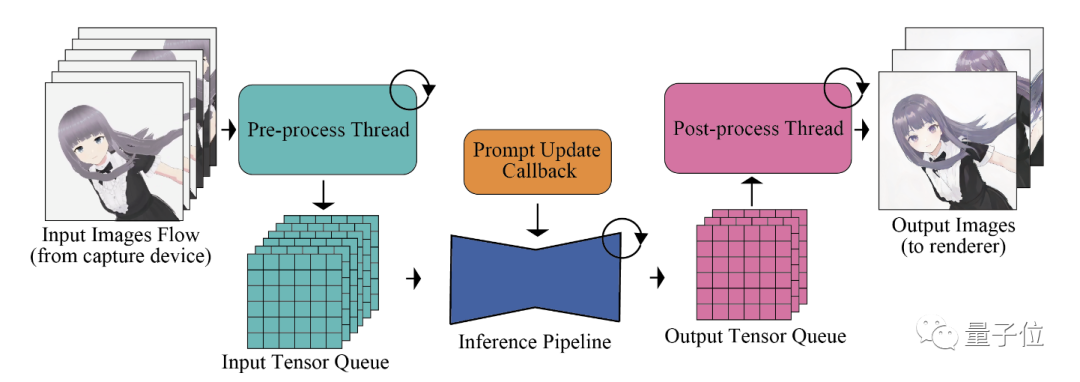
而输入-输出队列主要是利用队列存储缓冲输入和输出,将图像数据预处理等操作与UNet主体网络分隔开,实现pipeline各个处理环节的并行化,防止处理速度不匹配的情况发生。
随机相似性过滤器,可以基于图像相似性跳过一些UNet处理,减少不必要的计算量,降低功耗:

预计算则是提前缓存一些静态量,如提示嵌入、噪声样本等,减少每次生成的重复计算。

免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier

