

Paul Atkins是谁?正式担任
文章来源:量子位

图片来源:由无界 AI生成
微调,能让通用大模型更加适配具体的行业应用。
但现在,研究人员们却发现:
对多模态大模型做“多任务指令微调”,大模型可能会“学得多错得多”,因为不同任务之间的冲突,导致泛化能力下降。
举个例子,多模态问答任务可能要求回复尽可能简洁准确,文档理解任务却会反过来要求大模型尽可能详细地做出描述。
不同下游任务指令微调数据分布差异较大,导致一个大模型难以在多个下游任务中均达到最优性能。
如何解决这个问题?
来自香港科技大学、南方科技大学和华为诺亚方舟实验室的联合研究团队,受MoE(混合专家模型)开源大模型Mixtral-8×7B的启发,提出利用稀疏专家模型,打造下游任务泛化性能更好、理解能力更强的多模态大模型。

具体细节,一起来看。
为了验证多模态指令微调中不同类型任务数据对模型性能的影响,研究人员将数据进行如下划分:
基于以上数据,研究人员采用LoRA对InstructBLIP进行微调,获得3个专家模型,并在其他数据(Flickr30k-图像描述、GQA/SciQA/IconQA/TextVQA等不同类型视觉问答、HM/VSR等多模态分类或推理任务)上进行零样本测试和评估。
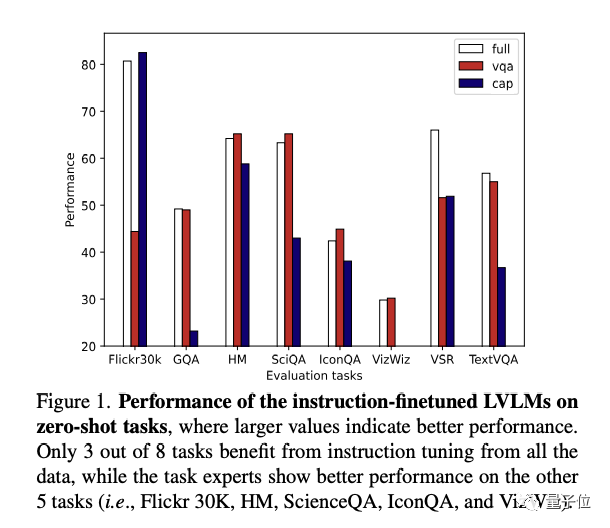
从上图(右)中可以看出,在指令微调中,并非采用全量数据会取得最好效果,相反,只有三个下游任务(GQA,VSR,TextVQA)在全量数据专家下表现最好。
这说明,对于大部分任务来说,在指令微调过程中引入其他任务的数据,反而会降低模型性能,多模态指令微调存在任务冲突。
另一方面,实验中观察到,VQA和Captioning两个专家模型,在各自任务中取得了相较于全量专家更好的表现。这样的方法看似解决了任务冲突的问题,但存在以下局限:
为了解决以上局限,研究团队提出,可以利用稀疏专家模型(MoE),不同的专家处理不同的任务,并设计一种数据划分的方法,把相似的任务交给同一个专家处理。

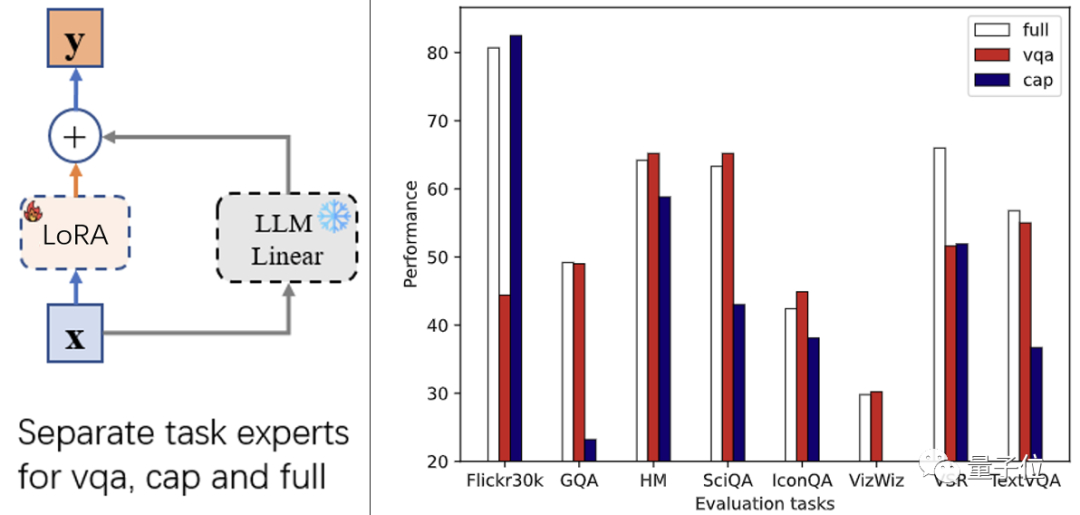
在大型视觉-语言模型(LVLM)中,该文定义指令为所有的文本输入,如上图(左)C1-C4的文本。
这些指令描述了任务的意图、要求。因此,作者使用Kmeans将所有的指令聚为64类。
如上图(右)所示,指令的聚类信息可以有效表示数据的任务类型。这样做省去了人力划分数据的成本。

和前面的任务专家相似,模型在该层的输出同样由冻结的LLM线性层以及微调的LoRA产生。
不同的是,这里利用数据的指令聚类信息来对混合LoRA进行路由。具体而言,对于的模型的输入,可以按照如下方式计算它的路由信息:
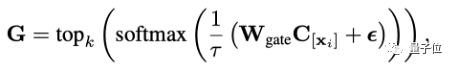
免责声明:数字资产交易涉及重大风险,本资料不应作为投资决策依据,亦不应被解释为从事投资交易的建议。请确保充分了解所涉及的风险并谨慎投资。OKEx学院仅提供信息参考,不构成任何投资建议,用户一切投资行为与本站无关。

和全球数字资产投资者交流讨论
扫码加入OKEx社群
industry-frontier
?如何")
?PUMP币")